Tina Afshar Ghochani, Defining Culture and People Related Processes in Advanced Data Analytics Projects
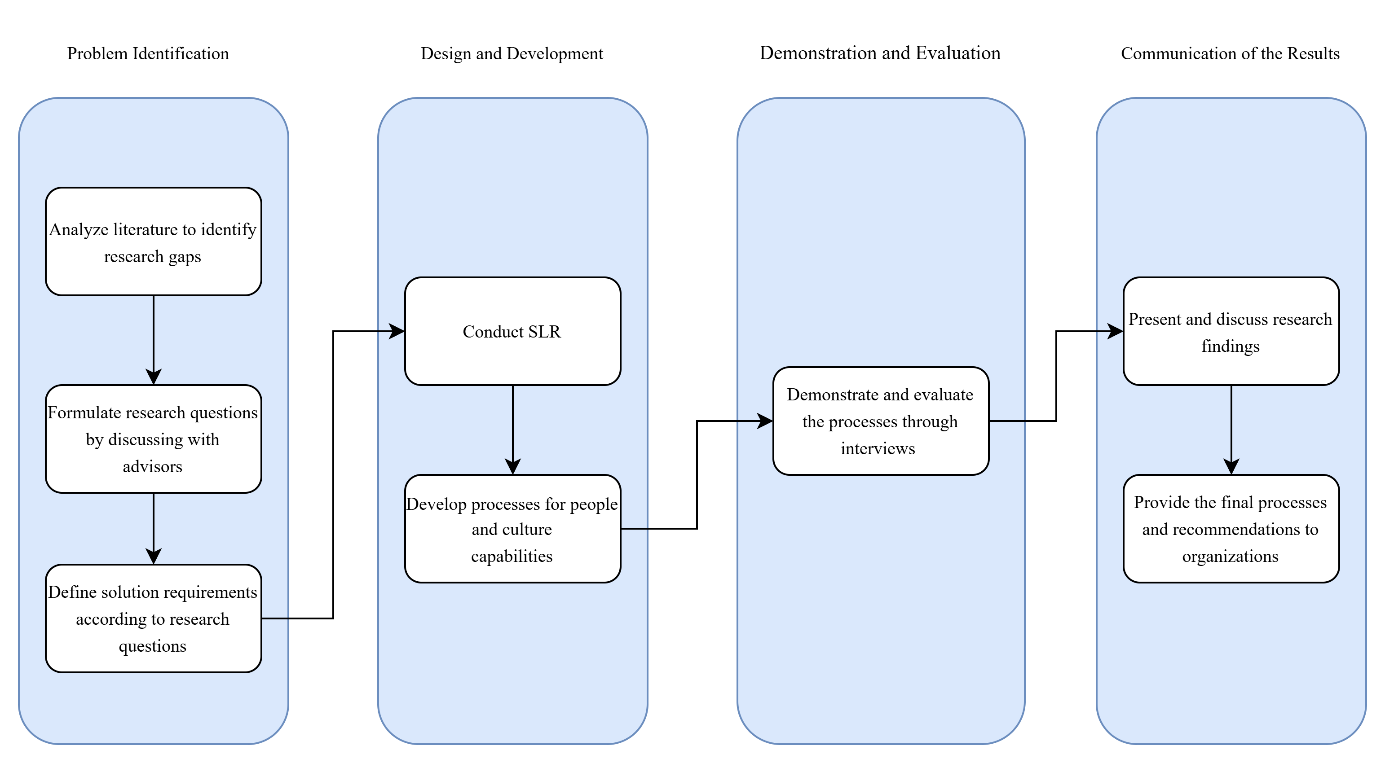
This thesis explores the critical role of people and culture-related capabilities in the success of Advanced Data Analytics (ADA) projects, addressing a gap in current literature that predominantly focuses on technical aspects. By conducting a systematic literature review and semi-structured interviews, the study identifies and categorizes these capabilities, integrating them into structured processes tailored from the People Capability Maturity Model (Curtis et al., 2009). The research contributes actionable frameworks and practices to enhance workforce readiness, collaboration, and organizational culture, enabling businesses to align ADA initiatives with strategic goals and achieve sustainable success.
Date: 10.01.2025 / 13:30 Place: A-212