Övgü Özdemir, Exploring the Capabilities of Large Language Models in Visual Question Answering: A New Approach Using Question-Driven Image Captions as Prompts
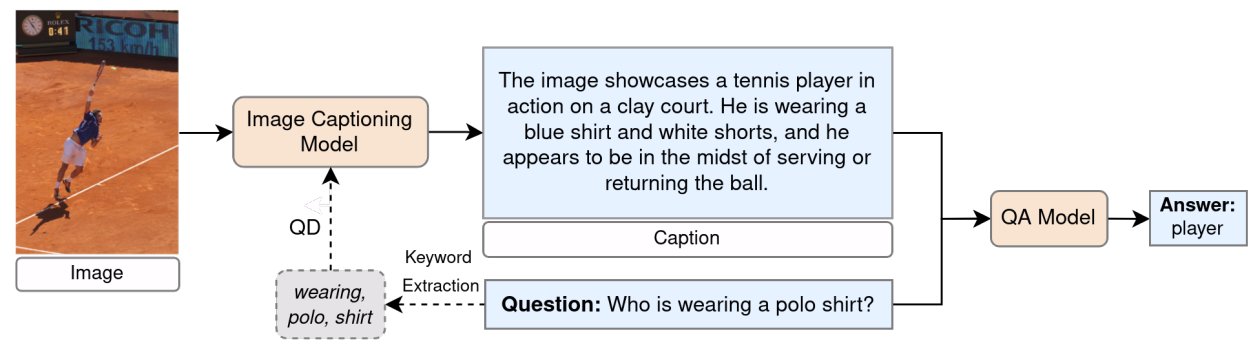
Visual Question Answering (VQA) is defined as an AI-complete task that requires understanding, reasoning, and inference of both visual and language content. Despite recent advancements in neural architectures, zero-shot VQA remains a significant challenge due to the demand for advanced generalization and reasoning skills. This thesis aims to explore the capabilities of recent Large Language Models (LLMs) in zero-shot VQA. Specifically, it evaluates the performance of multimodal LLMs such as CogVLM, GPT-4, and GPT-4o on the GQA dataset, which includes a diverse range of questions designed to assess reasoning abilities. A new framework for VQA is proposed, leveraging LLMs and integrating image captioning as an intermediate step. Additionally, the thesis examines the effect of different prompting techniques on VQA performance. Evaluations are conducted on questions that vary semantically and structurally. The findings highlight the potential of using image captions and optimized prompts to enhance VQA performance under zero-shot setting.
Date: 04.09.2024 / 13:30 Place: A-212