M.S. Candidate: Övgü Özdemir
Program: Multimedia Informatics
Date: 04.09.2024 / 13:30
Place: A-212
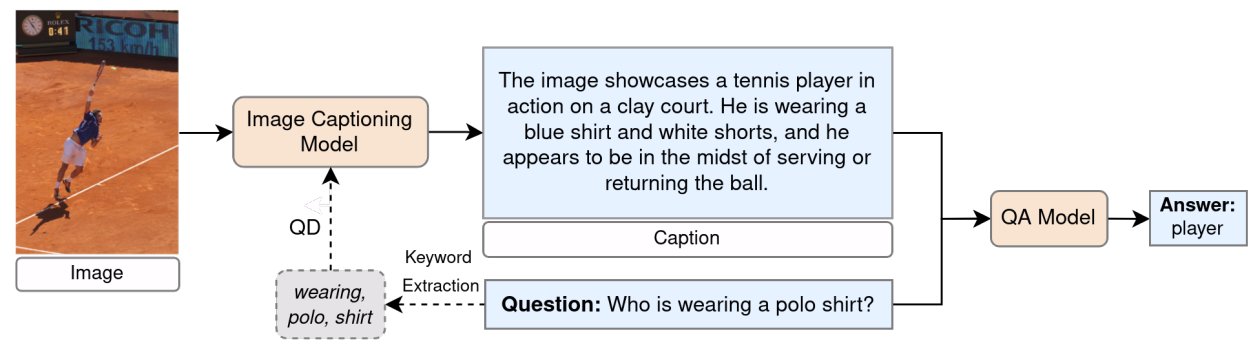
Abstract: Visual question answering (VQA) refers to the artificial intelligence task of providing natural language answers to natural language questions based on a visual input. Due to its requirement for multimodal processing, VQA is considered a challenging problem. It often necessitates understanding the scene depicted in the image, extracting the relationships between objects and their attributes, and performing multi-step reasoning. Over the past few years, numerous deep learning architectures have been proposed for VQA. More recently, pre-trained vision-language models and Multimodal LLMs with billions of parameters have demonstrated superior performance on benchmark tests. Nevertheless, there are still gaps for performance improvement in zero-shot VQA. Zero-shot VQA requires adapting to tasks without input-output guidance, necessitating advanced reasoning abilities. Consequently, recent research has focused on designing prompts that can elicit reasoning capabilities in MLLMs. This thesis proposes a new approach aimed at improving performance in zero-shot VQA by using LLMs and integrating context-aware image captioning as an intermediate step. Evaluations and comparisons were conducted using recent MLLMs, such as CogVLM, GPT-4, and GPT-4o, on the GQA test set, which includes structurally and semantically diverse questions that often require multi-step reasoning. Additionally, the thesis examines the impact of different prompt designs on VQA performance. The findings highlight the potential of using image captions and optimized prompts to enhance VQA performance under zero-shot settings.