



Announcements
Research News
Kompleks tat algısı ve bağırsak-beyin iletişimi, yeme davranışını etkiler. Vagus siniri (VN), yüksek kalorili gıdalara karşı duyarsızlaşarak aşırı yemeyi tetikleyebilir; bu süreç VN uyarımıyla tersine çevrilebilir. Bu çalışma, çikolatalı milkshake tüketimi sırasında oluşan sinirsel aktivitenin transkütanöz VNS (tVNS) tarafından modüle edilip edilmediğini EEG ile inceledi. Temel bulgular: (1) Gıda alımı sonrası spontan göz kırpma oranları (dopamin göstergesi) arttı, dopaminerjik süreçlerin aktivasyonuna işaret etti. (2) Yutma ile senkronize edilen olayla ilişkili potansiyeller (ERP’ler) yalnızca gıda uyaranı varlığında gözlendi; bu, yudumlama-yutma protokolünün kompleks tat araştırmaları için kullanılabileceğini destekledi. (3) Dinlenme halindeki beyin dalgaları veya ERP’ler üzerinde anlamlı tVNS etkisi bulunmadı, ancak yöntem gıdaya özgü sinirsel tepkileri tespit etti. Bu sonuçlar, protokolün gelecekteki bağırsak-beyin ekseni çalışmaları için kullanışlılığını da desteklemektedir.
Tarih: 14.04.2025 / 14:00 Yer: A-212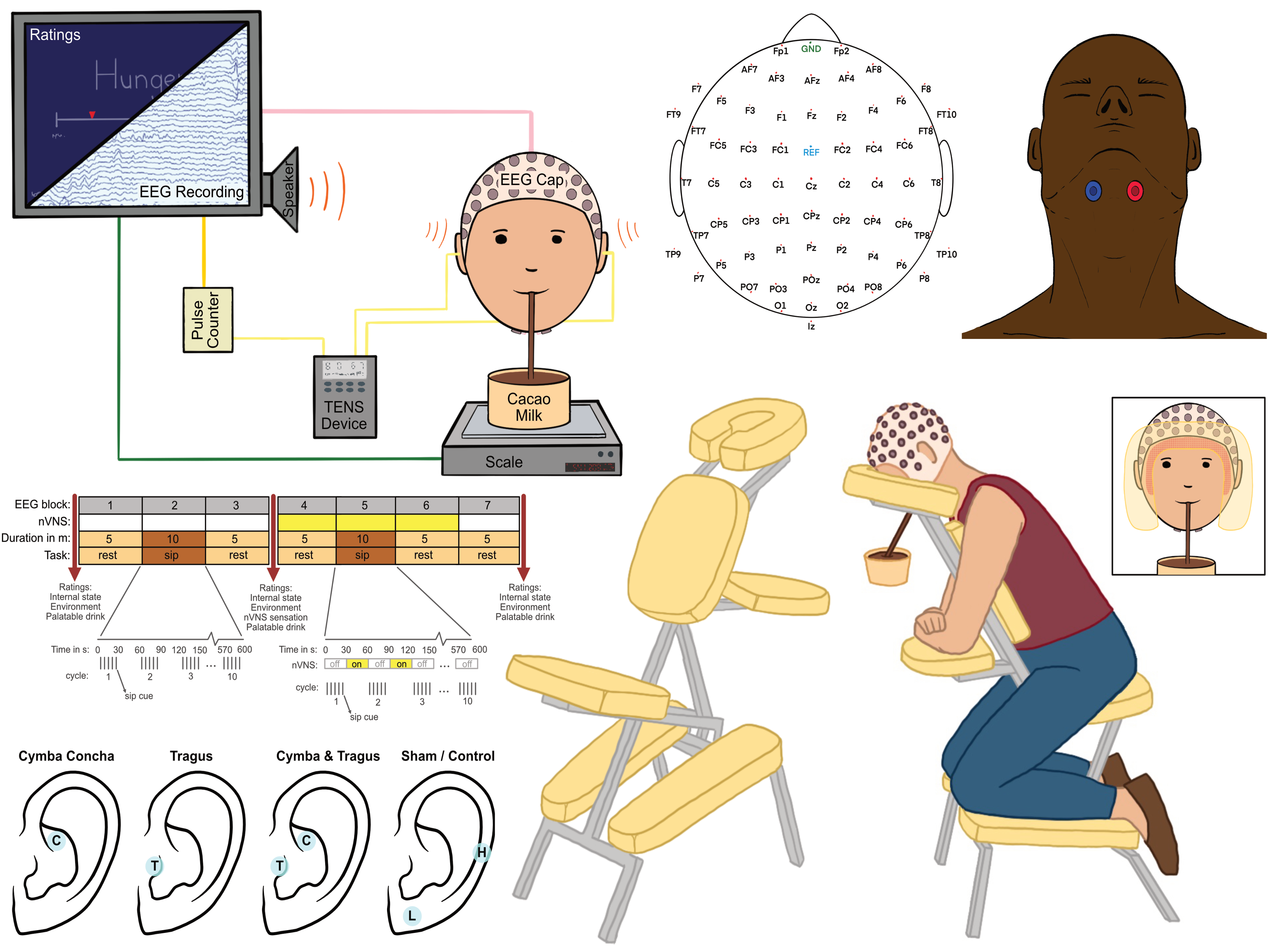
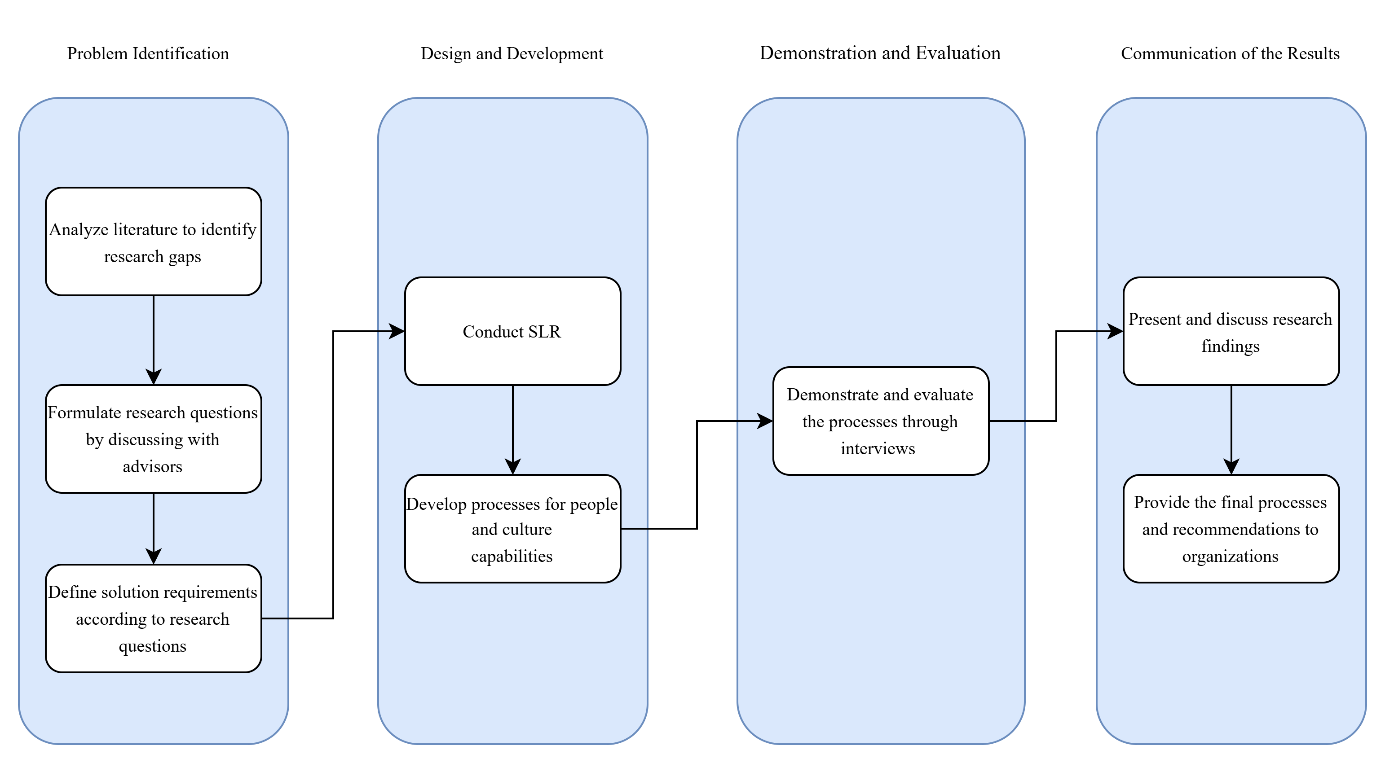
Bu tez, Gelişmiş Veri Analitiği (ADA) projelerinin başarısında insanların ve kültürle ilgili yeteneklerin kritik rolünü araştırarak, ağırlıklı olarak teknik yönlere odaklanan mevcut literatürdeki bir boşluğu ele almaktadır. Sistematik bir literatür incelemesi ve yarı yapılandırılmış görüşmeler gerçekleştirerek, çalışma bu yetenekleri belirleyip kategorilere ayırarak, bunları İnsan Yetenek Olgunluk Modeli'nden (Curtis vd., 2009) uyarlanmış yapılandırılmış süreçlere entegre etmektedir. Araştırma, iş gücü hazırlığını, iş birliğini ve kurumsal kültürü geliştirmek için eyleme geçirilebilir çerçeveler ve uygulamalar sunarak işletmelerin ADA girişimlerini stratejik hedeflerle uyumlu hale getirmelerini ve sürdürülebilir başarıya ulaşmalarını sağlamaktadır.
Tarih: 10.01.2025 / 13:30 Yer: A-212
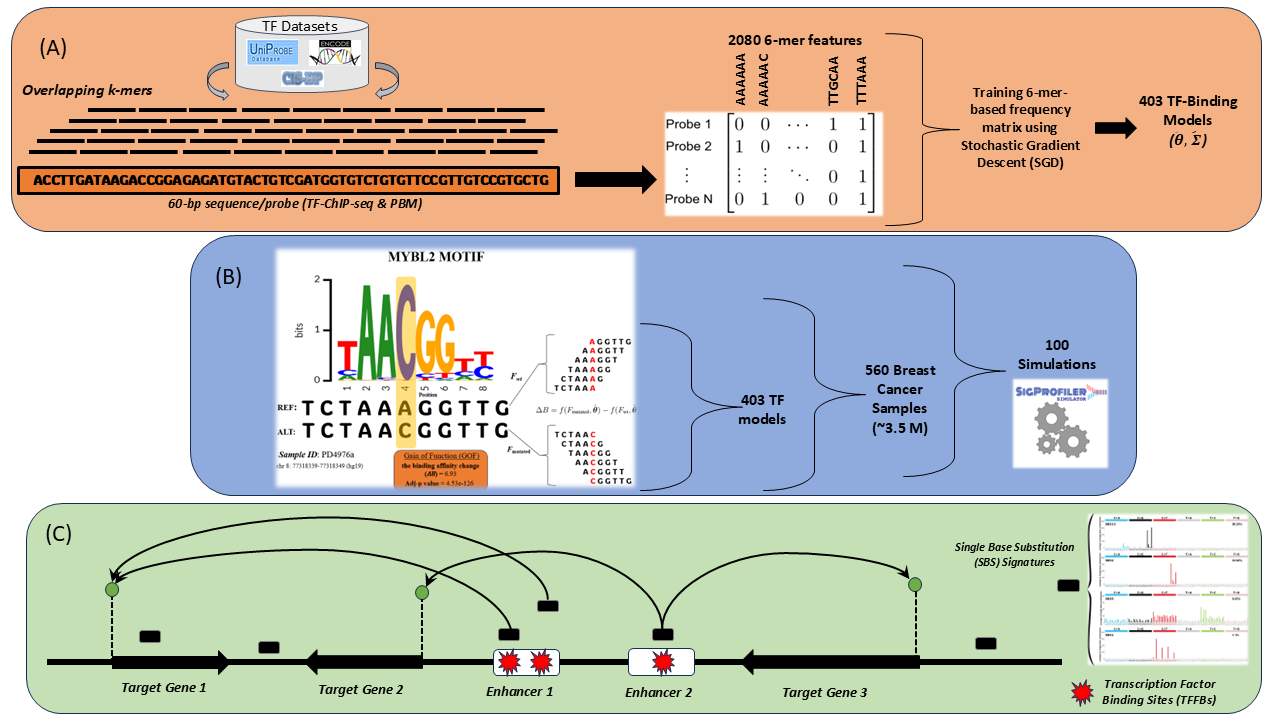
Kodlamayan bölgelerdeki somatik mutasyonlar, transkripsiyon faktörü (TF)-DNA etkileşimlerini bozarak gen düzenlemesini etkiler ve kansere katkıda bulunabilir. Bu tezde, somatik mutasyonların TF bağlanma afiniteleri üzerindeki etkisini değerlendiren bir in silico analiz hattı geliştirilmiştir. 403 TF için ChIP-seq ve PBM verileri kullanılarak eğitilen modellerle, 560 meme kanseri örneği incelenmiştir. Tahmin edilen TF bağlanma değişiklikleri kazanç veya kayıp fonksiyonu olarak sınıflandırılmış ve mutasyonla ilişkili hızlandırıcı-hedef gen haritalarıyla ilişkilendirilmiştir. Bu çalışma, istatistiksel analizlerle mutasyonel imza merkezli farklı desenler ve bulgular ortaya koyarken, somatik mutasyonların kanser üzerindeki düzenleyici rolüne dair önemli bilgiler sunmuştur.
Tarih: 07.01.2025 / 10:00 Yer: A-212
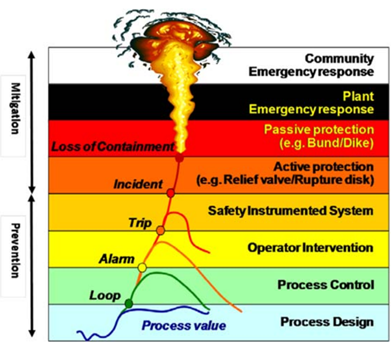
Tez, üretimde alarm yönetim sistemlerinin optimize edilmesini tartışmaktadır. Alarm parametrelerini geliştirmek için Tennessee Eastman Sürecini kullanan, gözden kaçan kritik alarmları azaltmayı ve proses güvenliğini iyileştirmeyi amaçlayan yeni bir veri odaklı yöntem sunar. Önemli katkılar arasında bozulmaların alarmlarla ilişkilendirilmesi, bir alarm simülasyon platformu oluşturulması ve alarm parametrelerinin optimize edilmesi yer alır. Çalışma, alarm reaksiyon gecikmesi ile alarm sayısı arasındaki dengeyi vurgulayarak operatörün zamanında yanıt vermesinin önemini vurgulamaktadır.
Tarih: 10.01.2025 / 14:45 Yer: II-06
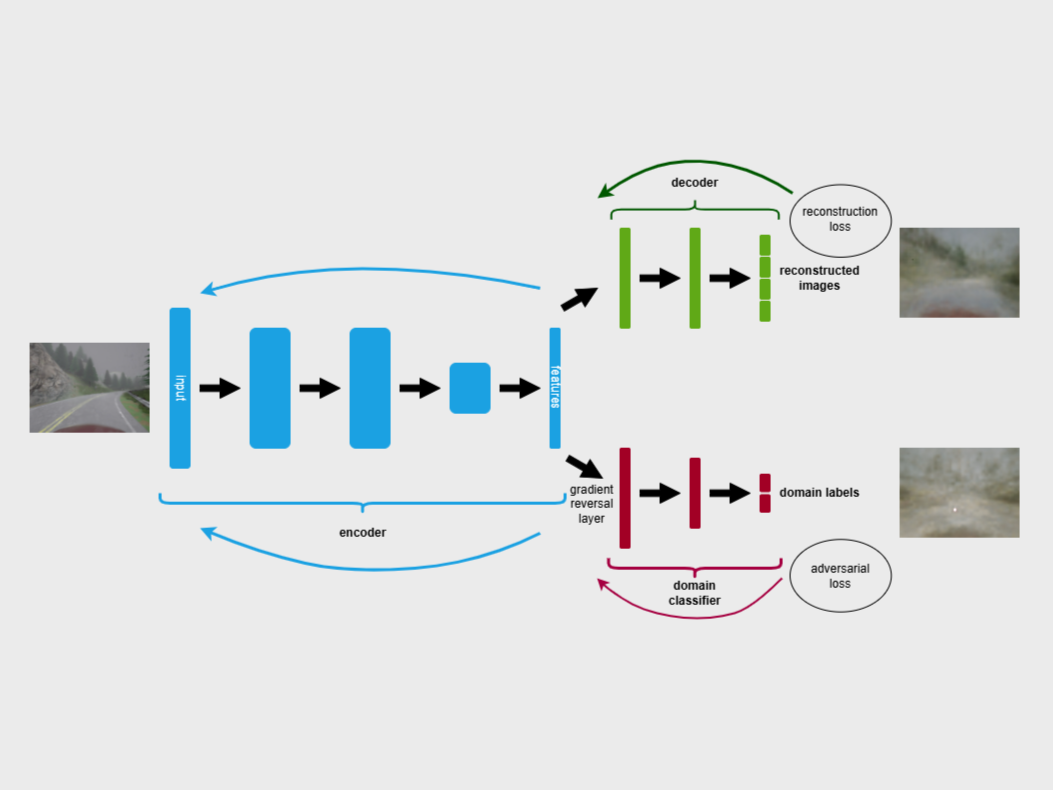
Bu tez, farklı bağlamlarda model genellenebilirliğini artırmak için denetimsiz alan uyarlaması kullanarak bağlamdan bağımsız otokodlayıcılar eğitimi için bir yöntem sunmaktadır. Alan-çekişmeli eğitim ve veri artırma stratejileri kullanılarak bağlam varyasyonlarını göz ardı eden, alan bağımsız temsiller çıkarılmıştır. Deneylerde, CARLA simülatöründen elde edilen çeşitli hava koşulları ve günün farklı saatlerine ait görüntü veri setleri kullanılmıştır. Önerilen çerçeve, yeniden yapılandırma kaybı ve özellik dayanıklılığını iyileştirerek dinamik ortamlarda güvenilir makine öğrenimi performansı sağlamaktadır. Çalışma, alan kaymalarını ele almadaki alan uyarlama tekniklerinin önemini vurgulayarak, otonom sistemler için sağlam bir temel sunmaktadır.
Tarih: 06.01.2025 / 14:30 Yer: A-212