
Announcements
Research News
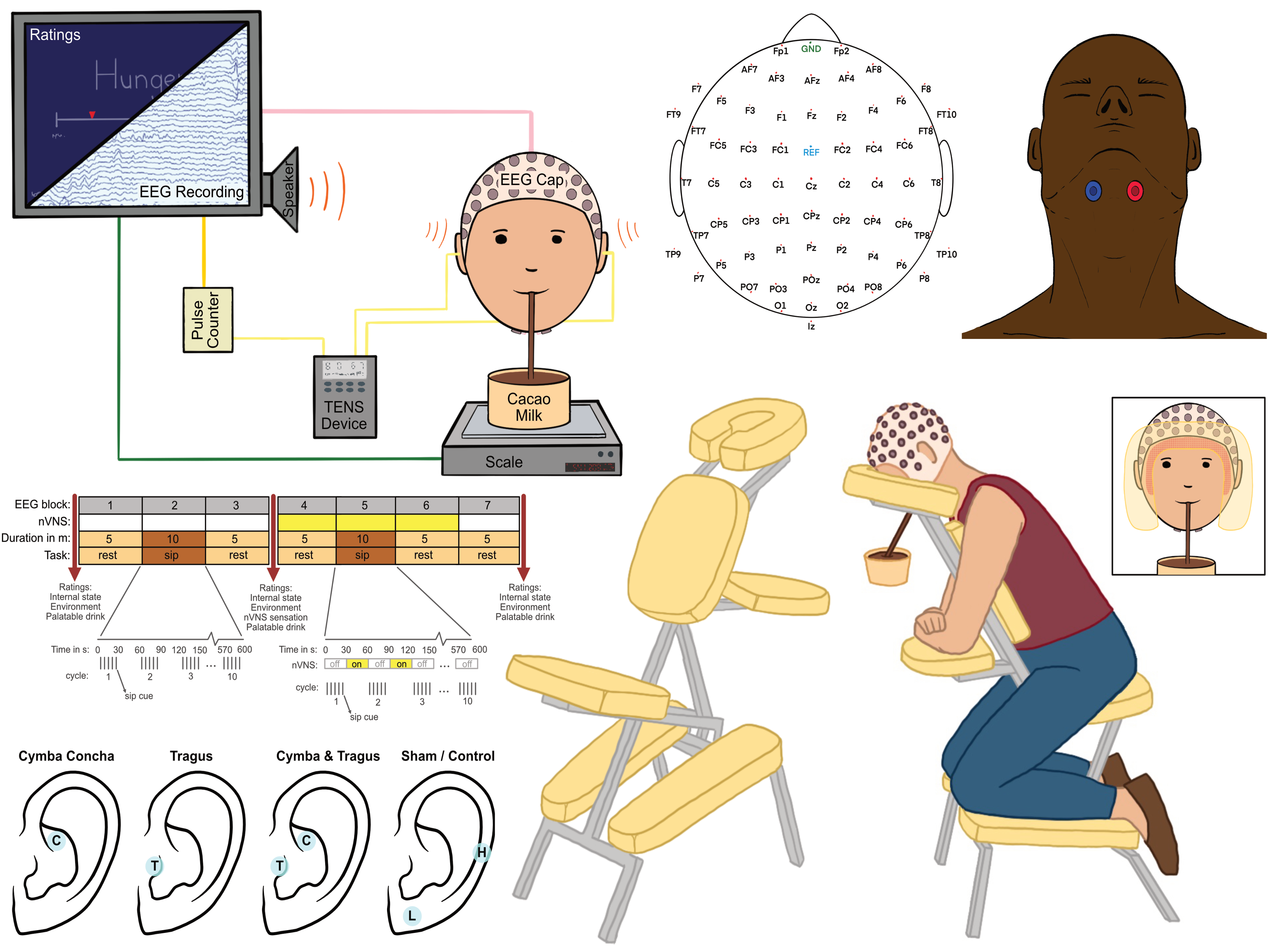
Flavor perception and gut-brain signaling influence eating behavior. The vagus nerve (VN) may become desensitized to high-calorie foods, promoting overeating, a process potentially reversible through VN stimulation. This study examined whether transcutaneous VNS (tVNS) modulates brain responses to food using EEG during chocolate milkshake consumption. Key findings: (1) Spontaneous eyeblink rates (a dopamine proxy) increased after food intake, suggesting dopaminergic engagement. (2) Event-related potentials (ERPs) time-locked to swallowing were only observed with food stimuli, validating the sip-and-swallow protocol for flavor research. (3) No significant tVNS effects were found on resting-state oscillations or ERPs, but the method captured food-specific neural responses. These results support the protocol’s utility for future gut-brain studies.
Date: 14.04.2025 / 14:00 Place: A-212
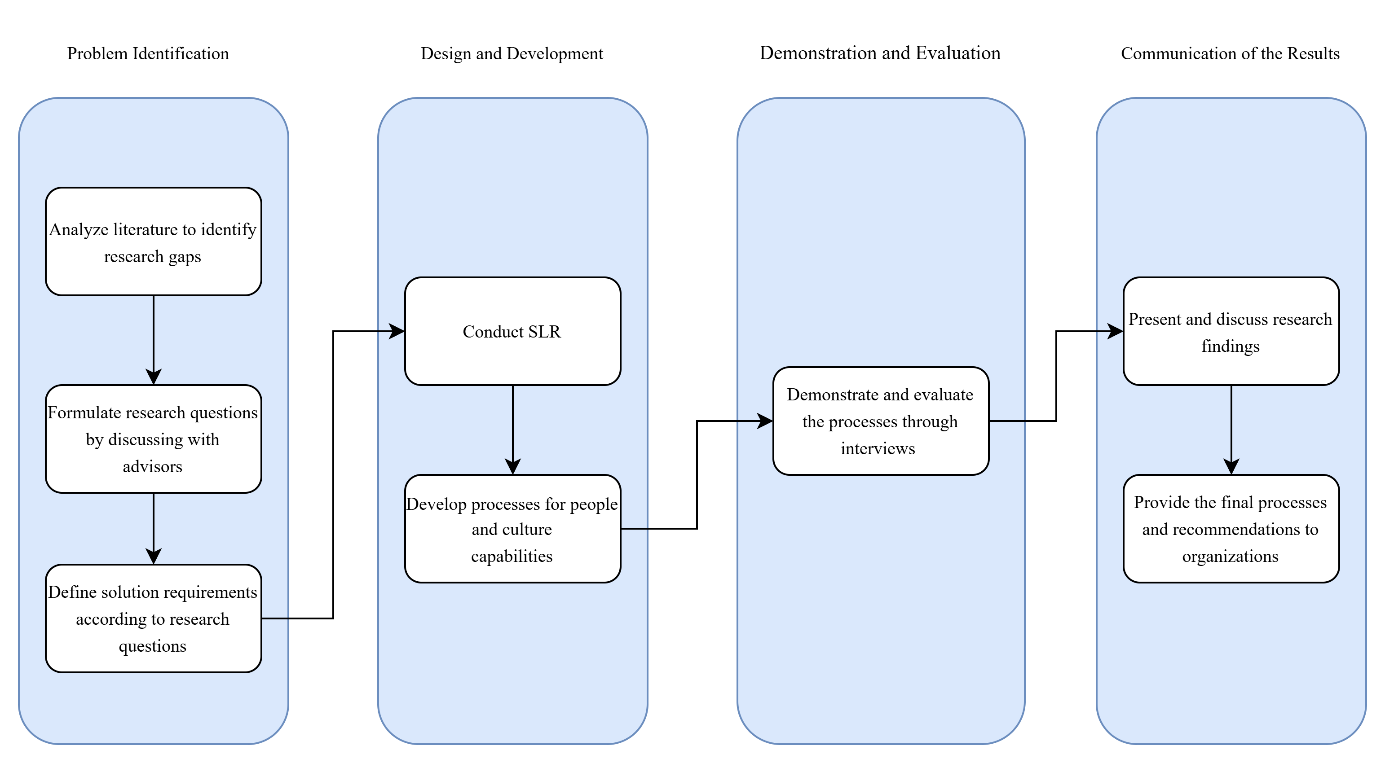
This thesis explores the critical role of people and culture-related capabilities in the success of Advanced Data Analytics (ADA) projects, addressing a gap in current literature that predominantly focuses on technical aspects. By conducting a systematic literature review and semi-structured interviews, the study identifies and categorizes these capabilities, integrating them into structured processes tailored from the People Capability Maturity Model (Curtis et al., 2009). The research contributes actionable frameworks and practices to enhance workforce readiness, collaboration, and organizational culture, enabling businesses to align ADA initiatives with strategic goals and achieve sustainable success.
Date: 10.01.2025 / 13:30 Place: A-212
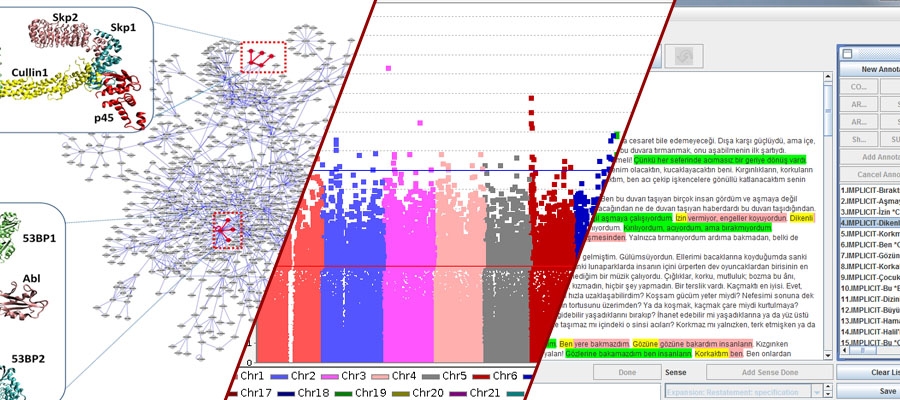
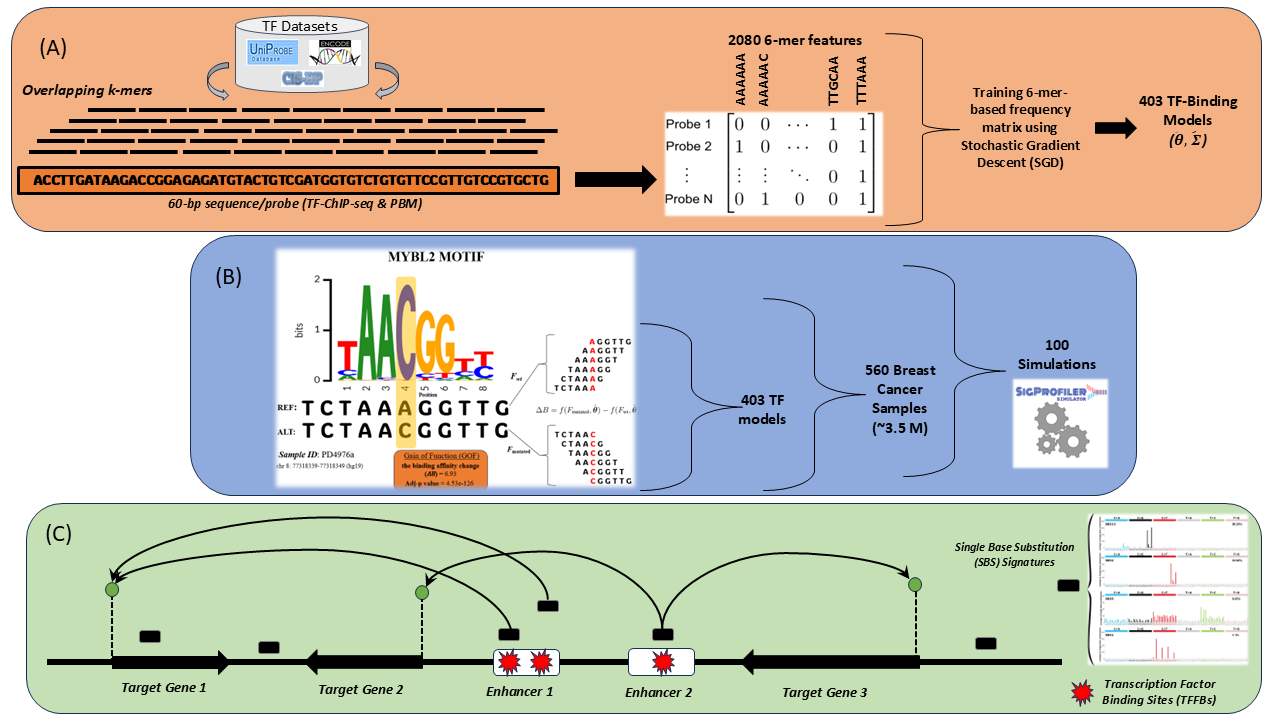
Somatic mutations in non-coding regions can disrupt transcription factor (TF)-DNA interactions, affecting gene regulation and contributing to cancer. This thesis introduces an in silico pipeline to assess the impact of these mutations on TF binding affinities. Using k-mer-based linear regression models trained on ChIP-seq and PBM data for 403 TFs, we analyzed somatic mutations in 560 breast cancer samples. Predicted TF binding changes were classified as gain or loss of function and linked to oncogene and tumor suppressor dysregulation using enhancer-target gene maps. Signature-specific and statistical analyses highlight distinct patterns, providing insights into the regulatory role of mutations in cancer.
Date: 07.01.2025 / 10:00 Place: A-212
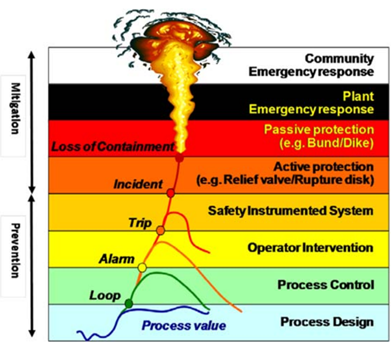
The thesis discusses optimizing alarm management systems in manufacturing. It introduces a novel data-driven method using the Tennessee Eastman Process to enhance alarm parameters, aiming to reduce missed critical alarms and improve process safety. Key contributions include associating disturbances with alarms, creating an alarm simulation platform, and optimizing alarm parameters. The study highlights the trade-off between alarm reaction delay and the number of alarms, emphasizing the importance of timely operator responses.
Date: 10.01.2025 / 14:45 Place: II-06
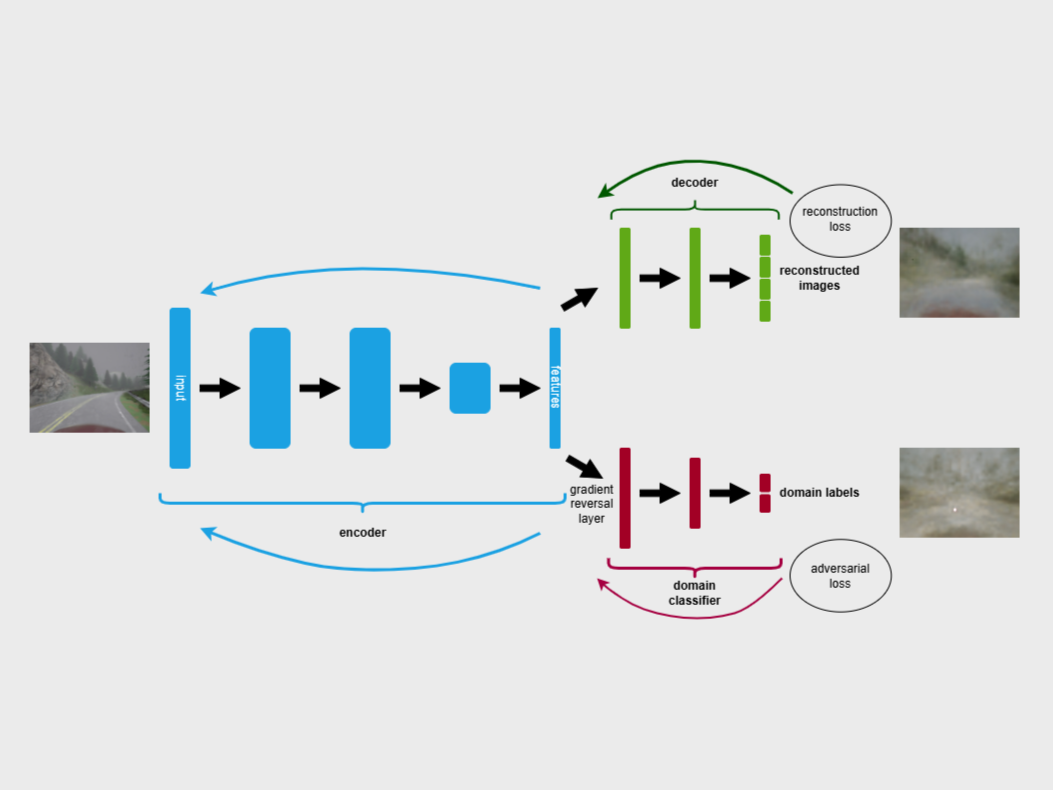
This thesis introduces a methodology for training context-invariant autoencoders using unsupervised domain adaptation to enhance model generalizability under varying contexts. By employing domain-adversarial training and data augmentation, the approach extracts domain-invariant representations while disregarding contextual variations. Experiments utilize the CARLA simulator, generating diverse image datasets across weather conditions and times of day. The proposed framework improves reconstruction loss and feature robustness, demonstrating its efficacy in achieving reliable machine learning performance in dynamic environments. The study emphasizes the utility of domain adaptation techniques in addressing domain shifts, offering a foundation for robust applications in autonomous systems.
Date: 06.01.2025 / 14:30 Place: A-212